Release 8.0
A58396-01
Library |
Product |
Contents |
Index |
| Oracle8 Backup and Recovery Guide Release 8.0 A58396-01 |
|
![]()
![]()
This chapter describes the basic concepts for the Oracle Recovery Manager utility, and includes the following topics:
Recovery Manager is an Oracle utility you use to back up, restore, and recover database files. Recovery Manager starts Oracle server processes on the database to be backed up or restored (called the target database). These Oracle server processes actually perform the backup and restore. For example, during a backup, the server process reads the files to be backed up, and writes out the files out to your target storage device.
Recovery Manager performs important backup and recovery procedures, and greatly simplifies the tasks administrators perform during these processes. For example, Recovery Manager provides a way to:
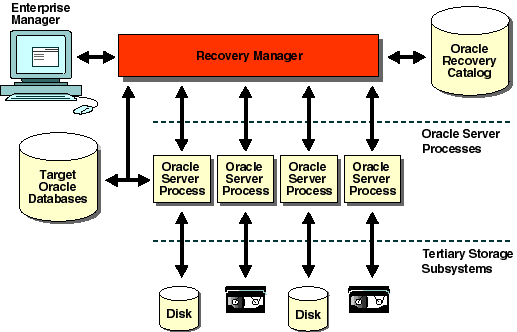
Recovery Manager has a command language interpreter (CLI), and can be executed in interactive or batch mode. You may also specify a log file on the command line to record significant Recovery Manager actions.You can also use Recovery Manager via the Enterprise Manager Recovery Manager application.
When running in batch mode, Recovery Manager reads input from a command file and writes output messages to a log file (if specified). The command file is parsed in its entirety before any commands are compiled and executed. Batch mode is most suitable for performing regularly scheduled backups via an operating system job control facility.
Recovery Manager provides the following categories of commands:
If you use Recovery Manager to perform backups to sequential media, such as tape, you must have media management software integrated with your Oracle software.
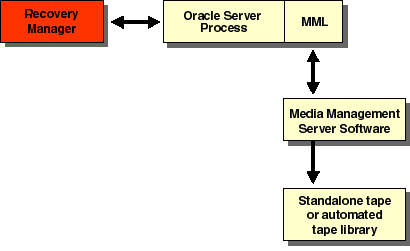
In Figure 7-2, the Oracle executable is the same executable that is started when a user connects to the database. MML is the Media Management Library, which is media management, vendor-supplied software. Software routines in the MML are called by Oracle to back up and restore.
In the following example, a Recovery Manager script performs a datafile backup:
run { allocate channel t1 type `SBT_TAPE'; backup format `df_%s_%t' (datafile 10); }
When Recovery Manager executes this command, it sends the backup request to the Oracle server process that will be performing the backup. The Oracle server process identifies the output channel as the type `SBT_TAPE', and requests the MML to load the tape and write the output, among other things.
If the channel type was disk, Oracle would not have connected to the MML software because Oracle can write to disk without the assistance of third-party integration software.
See Also: For information about vendors offering software integrated with Recovery Manager, see your Oracle representative.
You can perform Recovery Manager backups using Oracle Enterprise Manager-Backup Manager software, which is a graphical user interface to Recovery Manager.
See Also: See your operating system-specific documentation for more information.
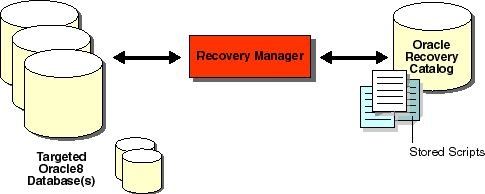
The recovery catalog is a repository of information that is used and maintained by Recovery Manager. Recovery Manager uses the information in the recovery catalog to determine how to execute requested backup and restore actions.
The recovery catalog contains informations about the following:
Oracle recommends you use Recovery Manager with a recovery catalog, especially if you have 20 (or more) datafiles. You must frequently resynchronize the recovery catalog with the target database control file to keep it up to date. The more up-to-date the recovery catalog is, the easier it will be to recover. For example, if you have 25 archive logs that have been created subsequent to the last resynchronization, and you experience a failure requiring that you restore the entire database and control file, you must first catalog these files with the recovery catalog before you can use them.
The recovery catalog is maintained solely by Recovery Manager, and the target database never accesses it directly. Recovery Manager propagates information about the database structure, archived redo logs, backup sets and datafile copies into the recovery catalog from the target database's control file.
You do not need an additional database which is solely for the recovery catalog. You can put the recovery catalog in an existing database. It is the database administrator's responsibility to make the recovery catalog database available to Recovery Manager. Database administrators are also responsible for taking backups of the recovery catalog. Since the recovery catalog resides in an Oracle database, administrators can use Recovery Manager to back it up by reversing the roles of the recovery catalog database and the target database. In other words, the target database can become the recovery catalog database and the recovery catalog database can be treated as a target database.
A single recovery catalog is able to store information for multiple target databases.
If the recovery catalog is destroyed and no backups are available, then you can partially reconstruct the catalog from the current control file or control file backups. However, you should always aim to have a valid, recent backup of your recovery catalog.
The size of the target database's control file will grow, depending on the number of:
You can specify the minimum number of days this information is kept in the control file using the parameter CONTROL_FILE_RECORD_KEEP_TIME. Entries older than the number of days are candidates for overwrites by newer information. The larger the CONTROL_FILE_RECORD_KEEP_TIME setting is, the larger the control file will be.
At a minimum, you should resynchronize your recovery catalog at intervals less than the CONTROL_FILE_RECORD_KEEP_TIME setting, because after this number of days, the information in the control file will be overwritten with the most recently created information; if you have not resynchronized, and information has been overwritten, this information can not be propagated to the recovery catalog.
|
Note: The maximum size of the control file is port specific. See your see your operating system-specific Oracle documentation. |
See Also: For more information about the CONTROL_FILE_RECORD_KEEP_TIME parameter, see the Oracle8 Reference.
Because most information in the recovery catalog is also available in the target database's control file, Recovery Manager supports an operational mode where it uses the target database control file instead of a recovery catalog. This operational mode is appropriate for small databases where installation and administration of another database for the sole purpose of maintaining the recovery catalog would be burdensome.
Note that the following features are not supported in this operational mode:
To restore and recover your database without using a recovery catalog, Oracle recommends that you:
The size of the target database's control file will grow, depending on the number of:
You can specify the minimum number of days this information is kept in the control file using the parameter CONTROL_FILE_RECORD_KEEP_TIME. Entries older than this number of days are candidates to be overwritten by newer information. The larger the CONTROL_FILE_RECORD_KEEP_TIME is, the larger the control file will be.
If you do not use a recovery catalog, you may wish to set the CONTROL_FILE_RECORD_KEEP_TIME parameter to the duration (in days) you intend to keep your backups. This way, the backup information in the control file will not be overwritten before the backups become obsolete.
|
Note: The maximum size of the control file is port specific. See your see your operating system-specific Oracle documentation. |
See Also: For more information about the CONTROL_FILE_RECORD_KEEP_TIME parameter, see the Oracle8 Reference.
Recovery Manager generates a snapshot control file, which is a temporary backup control file each time it refreshes the recovery catalog. This snapshot control file ensures that Recovery Manager has a consistent view of the control file either when refreshing the recovery catalog or when querying the control file (if you are not using a recovery catalog). Because the snapshot control file is for Recovery Manager's short term use, it is not registered in the recovery catalog. Recovery Manager records the snapshot control file checkpoint in the recovery catalog to indicate precisely how current the recovery catalog is.
The Oracle8 server ensures only one Recovery Manager session accesses a snapshot control file at any point in time. This is necessary to ensure that two Recovery Manager sessions do not interfere with each other's use of the snapshot control file.
|
Note: It is possible to specify the name and location of a snapshot control file. For information on how to do this, see "Configuring the Snapshot Control File Location". |
Database administrators can store a sequence of Recovery Manager commands, called a stored script, in the recovery catalog for execution at a later time. This allows the administrator to plan, develop and test a set of commands for backing up, restoring, and recovering the database. Stored scripts also minimize the potential for operator errors. Each stored script relates to only one database.
Recovery Manager supports two basic types of backups:
A backup set contains one or more datafiles or archivelogs; however, it cannot contain both datafiles and archivelogs. Datafile backup sets can also contain a control file backup.
Backup sets are in an Oracle proprietary format (similar to Export files). You must perform a restore operation to extract a file from a backup set.
A backup set is also complete set of backup pieces that constitute a full or incremental backup of the objects specified in the backup command.
The pieces of a backup set are written serially. (Striping a backup set across multiple output devices is not supported.) If multiple output devices are available, you can partition your backups so that multiple backup sets are created in parallel. Recovery Manager performs this backup partitioning automatically, if desired.
A backup set can:
You can write backup sets to either normal operating system disk files or to sequential output media (for example, magnetic tape) using a sequential output device or media management system that is available and supported by Oracle on your operating system. To determine which device types are supported by your operating system or Media Manager, query the V$BACKUP_DEVICE view.
A backup set containing archived logs is called an archivelog backup set. You cannot archive directly to tape. However, Recovery Manager allows you to back up archived logs from disk to tape. Also, during recovery Recovery Manager automatically stages the required archived logs from tape to disk.
See Also: For details about V$BACKUP_DEVICE, see the Oracle8 Reference.
A backup set is composed of one or more backup pieces, each piece being a single output file. You should restrict the size of a backup piece to whatever is the maximum file size supported by your Media Manager or O/S (if writing to disk). If you do not restrict this size, a backup set will be comprised of only one file.
Each backup piece contains control and checksum information that allows the Oracle server process to validate the correctness of the backup piece during a restore.
Datafile blocks that have never been used are not written out to backup sets. Image copy backups of a datafile always contain all datafile blocks.
Datafile blocks included in the same backup set are multiplexed together. This means that the blocks from all of the files in the set are interspersed with all the other blocks.
You can control the number of datafiles that are backed up concurrently to a backup set using the filesperset parameter. Controlling concurrency is helpful if you want to keep a tape device streaming without saturating a single datafile with too many read requests (which can subsequently degrade online performance). You can limit the read rate by using the set limit readrate channel command.
See Also: For a detailed description, see "Multiplexed Backup Sets".
Datafile backup sets can be full or incremental. A full backup is a backup of one or more datafiles that contain all blocks of the datafile(s). An incremental backup is a backup of one or more datafiles that contain only those blocks that have been modified since a previous backup. These concepts are described in more detail in the following sections.
A full backup copies all blocks into the backup set, skipping only datafile blocks that have never been used. No blocks are skipped when backing up archivelogs or control files.
A full backup is not the same as a whole database- backup; full is an indicator that the backup is not incremental.
Also, a full backup has no effect on subsequent incremental backups, and is not considered part of the incremental strategy (in other words, a full backup does not affect which blocks are included in subsequent incremental backups).
Oracle allows you to create and restore full backups of the following:
Archivelog backup sets are always full backups.
An incremental backup is a backup of one or more datafiles that contain only those blocks that have been modified since a previous backup at the same or lower level; unused blocks are not written out.
A control file may be included in an incremental backup set; however, it is always included in its entirety (in other words, the full control file is always included; no blocks are skipped).
Oracle allows you to create and restore incremental backups of the following:
The multi-level incremental backup feature allows you to create different levels of incremental backups. Each level is denoted by an integer. By default, an incremental backup at any particular level consists of those blocks that have been modified since the last backup at that level or lower.
A level 0 incremental backup copies all blocks containing data; a level 0 incremental backup is the base for subsequent incremental backups.
An incremental backup at a level greater than 0 copies only those blocks that have changed since a previous incremental backup at the same or lower level. Hence, the benefit of performing incremental backups is that you don't back up all of the blocks all of the time. Incremental backups at levels greater than 0 only copy blocks that were modified. This means the backup size may be significantly smaller, and require much less time. The size of the backup file depends solely upon the number of blocks modified, as well as the incremental backup level chosen by the DBA.
The multi-level incremental backup feature allows you to devise a backup scheme that enables you to restore the database within a given time constraint. For example, you could implement a three-level backup scheme so that a level 0 backup was a monthly full backup; a level 1 backup was a weekly incremental, and a level 2 was a daily incremental.
Oracle provides an option to make cumulative incremental backups at level 1 or greater. Cumulative incremental backups reduce the work needed for a restore by ensuring that you only need one incremental backup from any particular level at restore time. However, cumulative backups require more space and time because they duplicate the work done by previous backups at the same level.
A cumulative incremental backup copies all blocks that have changed since a previous incremental backup at a lower level.
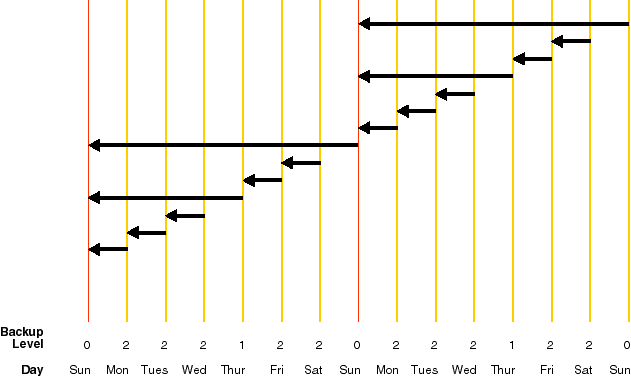
In the example above:
An incremental level 0 backup occurs. This backs up all blocks that have ever been in use in this database.
An incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n or less; in this case the most recent incremental backup at level 2 or less is the level 0 Sunday backup, so only the blocks changed since Sunday will be backed up.
An incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n or less; in this case the most recent incremental backup at level 2 or less is the level 2 Monday backup, so only the blocks changed since Monday will be backed up.
An incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n or less; in this case the most recent incremental backup at level 2 or less is the level 2 Tuesday backup, so only the blocks changed since Tuesday will be backed up.
An incremental level 1 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n or less; in this case the most recent incremental backup at level 1 or less is the level 0 Sunday backup, so only the blocks changed since the Sunday level 0 backup will be backed up.
An incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n or less; in this case the most recent incremental backup at level 2 or less is the level 1 Thursday backup, so only the blocks changed since the Thursday level 1 backup will be backed up.
An incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n or less; in this case the most recent incremental backup at level 2 or less is the level 2 Thursday backup, so only the blocks changed since the Friday level 2 backup will be backed up.

In the example above:
An incremental level 0 backup occurs. This backs up all blocks that have ever been in use in this database.
A cumulative incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n-1 or less; in this case the most recent incremental backup at level 2-1 or less is the level 0 Sunday backup, so only the blocks changed since Sunday will be backed up.
A cumulative incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n-1 or less; in this case the most recent incremental backup at level 2-1 or less is the level 0 Sunday backup, so all the blocks changed since Sunday will be backed up. (This includes those which were copied on Monday, as this backup is "cumulative" and includes the blocks copied at backups taken at the same incremental level as the current backup).
A cumulative incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n-1 or less; in this case the most recent incremental backup at level 2-1 or less is the level 0 Sunday backup, so all the blocks changed since Sunday will be backed up. (This includes those which were copied on Monday & Tuesday, as this backup is cumulative and includes the blocks copied at backups taken at the same incremental level as the current backup).
A cumulative incremental level 1 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n-1 or less; in this case the most recent incremental backup at level 1-1 or less is the level 0 Sunday backup, so all the blocks changed since Sunday will be backed up.
A cumulative incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n-1 or less; in this case the most recent incremental backup at level 2-1 or less is the level 1 Thursday backup, so all the blocks changed since Thursday will be backed up.
A cumulative incremental level 2 backup occurs. This backs up all blocks that have changed since the most recent incremental backup at level n-1 or less; in this case the most recent incremental backup at level 2-1 or less is the level 1 Thursday backup, so all the blocks changed since Sunday will be backed up.
An image copy contains a single file (datafile, archivelog, or control file) that you can use as-is to perform recovery. An image copy backup is similar to an O/S copy of a single file, except it is produced by an Oracle server process, which performs additional actions like validating the blocks in the file, and registering the copy in the control file. An image copy differs from a backup set because it is not multiplexed, nor is there any additional header or footer control information stored in the copy.
Image copy backups may be written only to disk.
If the image copy is of a datafile, then no restore operation is required; a switch command is provided to point the control file at the copy and update the recovery catalog to indicate that the copy has been "consumed;" this is equivalent to the SQL statement ALTER DATABASE RENAME DATAFILE. You can then perform media recovery to make the copy current.
An image copy can be restored to another location to prevent the "consumption" of the copy, but a restore is not strictly necessary because the datafile can be renamed to the image copy.
Image copies (also known as O/S copies) created by mechanisms other than Recovery Manager are supported. However, database administrators must catalog such O/S copies with Recovery Manager before using them in a restore or switch.
Support for both closed and open O/S copies is provided for users who have other mechanisms for creating image copies of datafiles. For example, some sites store their datafiles on mirrored disk volumes. This permits the creation of image copies by simply breaking the mirrors. After the mirror has been broken, Recovery Manager can be notified of the existence of a new copy, thus making it a candidate for use in a restore. The database administrator must notify Recovery Manager when the copy is no longer available for restore (using the change ... uncatalog command). In this example, if the mirror is resilvered (not including other copies of the broken mirror), you must use a change ... uncatalog to update the recovery catalog and indicate that this copy is no longer available.
As it is an Oracle server process which is performing a backup or copy, the server process is able to detect many types of corrupt blocks. Each new corrupt block not previously encountered in a backup or copy operation is recorded in the control file and in the alert log.
Recovery Manager queries this information at the completion of a backup and stores it in the recovery catalog. You can query this information from the control file using the views V$BACKUP_CORRUPTION and V$COPY_CORRUPTION.
If you encounter a datafile block during a backup that has already been identified as corrupt by the database, then the corrupt block is copied into the backup and the corruption is reported to the control file as either a logical or media corruption.
If a datafile block is encountered with a corrupt header that has not already been identified as corrupt by the database, then the block is written to the backup with a reformatted header indicating the block is media corrupt.
A channel must be allocated before issuing a backup, copy, restore, or recover command. Each allocate channel command establishes a connection from Recovery Manager to a target database instance by starting a server process on the target instance. The allocate channel command also specifies the type of I/O device that the server process will use to perform the backup or restore operation. Each channel usually corresponds to one output device, unless your MML (Media Management Library) is capable of hardware multiplexing. Oracle does not recommend hardware multiplexing of Oracle backups. Note that there is only one Recovery Manager process communicating with one or many server processes attached to the target database.
You can allocate multiple channels, thus allowing multiple backup sets or file copies to be read or written in parallel by a single Recovery Manager command. Thus, the degree of parallelism within a command is affected by the number of channels (connections) that are allocated.
Each allocate channel command uses a separate connection to the target database. You can specify a different connect string for each channel, to connect to different instances of the target database. This is useful in an Oracle Parallel Server configuration for distributing the workload across different nodes.
Channel control commands can be used to:
On some platforms, these commands specify the name or type of I/O device to use. On other platforms, these commands specify which O/S access method or I/O driver to use. Not all platforms support the selection of I/O device through this interface; on some platforms, I/O device selection is controlled through platform-specific mechanisms.
Whether or not the allocate channel command actually causes O/S resources to be allocated is O/S dependent. Some operating systems allocate resources at the time the command is issued; others do not allocate resources until a file is opened for reading or writing. Furthermore, when type disk is specified, no O/S resources are allocated, other than for the creation of the server process.
A channel must be allocated before issuing a change ... delete command, which calls the O/S to delete a file. A channel which is allocated in this way is useful only for deleting files. It cannot be used as an input or output channel for a job. Only one such channel can be allocated at a time.
Recovery Manager may parallelize its operations, establishing multiple logon sessions and conducting multiple backup sets or file copies in parallel. Concurrent backup sets or image copies must operate on disjoint sets of database files.
Parallelization of backup, copy, and restore commands is handled internally by the Recovery Manager. You only need to specify:
You typically must specify the number of files per set for backup sets. For example, if you allocate 20 channels, but perform a simple backup (database) of a database containing 20 files without any other options specified, only one channel will be used, even though 20 are allocated. If you add `filesperset 4', then Recovery Manager will use 5 channels (limiting each channel to 4 files). Specifying 'filesperset 1' indicates that each channel can operate on only 1 file; thus all 20 channels will be used.
In the example above, if you back up the same database (20 files) and each file corresponds one-to-one with a tablespace, and you write the backup command as follows, you do not need to use filesperset to parallelize:
backup (tablespace 1 tablespace 2 ... tablespace 20)
Recovery Manager executes commands serially, that is, it completes the current command before starting the next command. Parallelism is exploited only within the context of a single command. Thus, if you want 10 datafile copies, it is better to issue a single copy command specifying all 10 copies rather than 10 separate copy commands
For file copies, specify multiple datafiles to copy in a single copy command. For example, the following Recovery Manager script serializes the file copies. Only one channel is active at any one time.
run { allocate channel c1 type disk; allocate channel c2 type disk; allocate channel c3 type disk; allocate channel c4 type disk; allocate channel c5 type disk; allocate channel c6 type disk; allocate channel c7 type disk; allocate channel c8 type disk; allocate channel c9 type disk; allocate channel c10 type disk; copy datafile 22 to '/dev/prod/backup1/prod_tab5_1.dbf'; copy datafile 23 to '/dev/prod/backup1/prod_tab5_2.dbf'; copy datafile 24 to '/dev/prod/backup1/prod_tab5_3.dbf'; copy datafile 25 to '/dev/prod/backup1/prod_tab5_4.dbf'; copy datafile 26 to '/dev/prod/backup1/prod_tab6_1.dbf'; copy datafile 27 to '/dev/prod/backup1/prod_tab7_1.dbf'; copy datafile 28 to '/dev/prod/backup1/prod_tab5_2.dbf'; copy datafile 29 to '/dev/prod/backup1/prod_ndx5_1.dbf'; copy datafile 30 to '/dev/prod/backup1/prod_ndx5_2.dbf'; copy datafile 31 to '/dev/prod/backup1/prod_ndx5_3.dbf'; }
The following statement parallelizes the same example; there is one Recovery Manager command copying 10 files, and 10 channels available. All 10 channels are concurrently active--each channel copies one file.
run { allocate channel c1 type disk; allocate channel c2 type disk; allocate channel c3 type disk; allocate channel c4 type disk; allocate channel c5 type disk; allocate channel c6 type disk; allocate channel c7 type disk; allocate channel c8 type disk; allocate channel c9 type disk; allocate channel c10 type disk; copy datafile 22 to '/dev/prod/backup1/prod_tab5_1.dbf', datafile 23 to '/dev/prod/backup1/prod_tab5_2.dbf', datafile 24 to '/dev/prod/backup1/prod_tab5_3.dbf', datafile 25 to '/dev/prod/backup1/prod_tab5_4.dbf', datafile 26 to '/dev/prod/backup1/prod_tab6_1.dbf', datafile 27 to '/dev/prod/backup1/prod_tab7_1.dbf', datafile 28 to '/dev/prod/backup1/prod_tab5_2.dbf', datafile 29 to '/dev/prod/backup1/prod_ndx5_1.dbf', datafile 30 to '/dev/prod/backup1/prod_ndx5_2.dbf', datafile 31 to '/dev/prod/backup1/prod_ndx5_3.dbf'; }
A server process can concurrently operate on one or more files and/or tablespaces. If multiple files and/or tablespaces are specified, or one or more multi-file tablespaces are specified, then the datafiles are backed up concurrently and the output is multiplexed together. This means blocks from files in the same backup set will be interspersed with each other throughout the backup set.
When executing a multiplexed backup (multiple datafiles written to the same backup set), you can either partition the datafiles into backup sets explicitly, or let Recovery Manager automatically select a partitioning.
A high performance sequential output device can be kept streaming by including a sufficient number of datafiles in the backup. This is important for open database backups where the backup operation must compete with the online system for I/O bandwidth.
The control file may also be included in a datafile backup set. The Oracle logical blocksize of the objects in a multiplexed backup must be the same. Hence, datafiles and archive logs cannot be written to the same set.
The report and list commands provide information about backups and image copies. While the list command simply lists the contents of the recovery catalog, the report command performs a more detailed analysis of the recovery catalog. The output from these commands is written to the message log file.
The report command produces reports that can answer questions such as:
The report need backup and report unrecoverable commands should be used on a regular basis to ensure that the necessary backups are available to perform recovery, and to ensure that the recovery can be performed within a reasonable length of time. The report command lists backup sets and datafile copies that can be deleted either because they are redundant or because they could never be used by a recover command.
A datafile is considered unrecoverable if an unrecoverable operation has been performed against an object residing in the datafile subsequent to the last backup.
The list command queries the recovery catalog and produces a listing of its contents. You can use it to find out what backups or copies are available:
See Also: For more details on the Recovery Manager report command, see Appendix A, "Recovery Manager Command Syntax".
You can optionally assign a user-specified character string called a tag to backup sets and image copies (either Oracle-created copies or user-created copies). A tag is essentially a symbolic name for a backup set or file copy, and can be specified when executing the restore or change command. A tag provides a symbolic way to refer to a collection of file copies or backup sets. The maximum length of a tag is 30 characters.
Tags need not be unique: multiple backup sets or image copies can have the same tag. When a tag is not unique, then with respect to a given datafile, the tag is understood to refer to the most current suitable file (that is, the most current suitable backup containing that file may not be the most recent backup; this situation would occur when performing a point-in-time recovery). For example, if datafile copies are created each Monday evening and are always tagged "mondayPMcopy", then the tag is considered to refer to the most recently created copy. Thus, the following command switches datafile three to the most recently created Monday evening copy:
switch datafile 3 to datafilecopy tag mondayPMcopy;
Tags can indicate the intended purpose or usage of different classes of backups or file copies. For example, datafile copies that are suitable for use in a switch can be tagged differently from file copies that should be used only for restore.
|
Note: By default, Recovery Manager selects the most recent backups to restore, unless qualified by a tag or an until clause. |
See Also: For information about the switch and restore commands, see Appendix A, "Recovery Manager Command Syntax."
Backup operations may be performed only by an instance that has the database mounted or open. In an Oracle parallel server environment, if the instance where the backup operation is being performed does not have the database open, then the database must not be open by any instance.
Backups are supported at both the tablespace and datafile level. Backups of the control file may also be created. Backups of online logs are not supported. (If backups of the online logs are desired, you must run the database in ARCHIVELOG mode.)
Recovery Manager does not back up:
See Also: "Backing Up Online Redo Logs".
Restore operations must be performed on a started instance, however, the instance need not have the database mounted. This allows restore operations to be performed when the control file has been lost. A tablespace/datafile that is to be restored must be offline, or the database must be closed.
A restore may either overwrite the existing datafiles or its output may be directed to a new file via the set newname command.
Oracle prohibits any attempts to perform operations which would result in unusable backup files or corrupt restored datafiles. Among the integrity checks that the Oracle Server performs are:
When performing open backups without using Recovery Manager, tablespaces must be put in hot backup mode in case the operating system reads a block for backup that is currently being written by DBW0, and is thus inconsistent. This phenomenon is known as "split" or "fractured blocks."
When performing a backup using Recovery Manager, an Oracle server process reads the datafiles, not an operating system utility. The Oracle server process reads whole Oracle blocks, and checks to see whether the block is fractured by comparing control information stored in the header and footer of each block. If a fractured block is detected, the Oracle server process rereads the block. This is why, when using Recovery Manager to back up or copy database files, tablespaces do not need to be in hot backup mode.
See Also: For information about hot backup mode, see Chapter 11, "Performing Operating System Backups".
The control file tracks the location of logs archived by the ARCH background process. Each time a log is successfully archived, a record is added to the control file. The record contains the archived log filename and other relevant information.
You can specify the number of archive log records maintained when creating the control file. Any number may be specified provided that the limit on total control file size is not exceeded. These records are reused in a circular fashion. Recovery Manager queries these records and propagates them into the recovery catalog.
If there is a media failure in an online log, it may not be possible to archive it. You may therefore choose to issue an ALTER DATABASE CLEAR UNARCHIVED LOG statement. In this case, an archive log record is still created, but it indicates that no archive log exists for this log sequence number/SCN range.
Recovery Manager can catalog an image copy and read the meta-data. This is important when the recovery catalog is lost and you must perform disaster recovery. Only image copies and archived logs can be cataloged.