The reason why I lost all the MC finables and only made all the ghosts
is that the Hough table has many empty bins.
For a given "gamma" value, the empty bins are filled by the values
obtained by the interpolation bewtween two nearest non-empty bins.
After the smoothing step, Hough table looks more beautiful... Compare with
what you saw in the phone conference Mar. 1, 1999.
Hough table should be regenerated later with more tracks & with various options (MS switch on, average Energy loss) for better study, but I think this table may not so bad at this beginning stage of Hough PR.
A new central event sample and single track samples
I realized that I was using the event sample "cv0_full_10.aou" which was created with the geometry 4.2. But the current hough table is made with the geometry 4.4. I am not sure whether there has been a change on the geometry for Spectrometer. So I dropped the event and I have produced an event with the data file "Phat/phatpmc/dat/std_auaudata" with the geometry 4.4. All the simulation is done with MULS 1 and LOSS 3 (both are defaults). From now on I work with this single typical Au-Au data (I guess this was produced by HIJING)
Here is the event display after the reconstruction by Hough table from
the event:
l
I have also produced some single track samples.
100 pion - :
200MeV at theta = 42
300MeV at theta = 43
400MeV at theta = 44
500MeV at theta = 45
100 pion + :
500MeV at theta = 45
400MeV at theta = 46
300MeV at theta = 47
200MeV at theta = 48
Track Seed Finder and its efficiency
Track seeds are reconstucted by a fixed-cone clustering algorithm (PHAT
interface to Mulguisin algorithm : TPhTrackSeedFinder). Big cone may cause
bad clustering, for example two real tracks into a cluster. Too small cone
may yield poor efficiency because of Multiple Scattering.
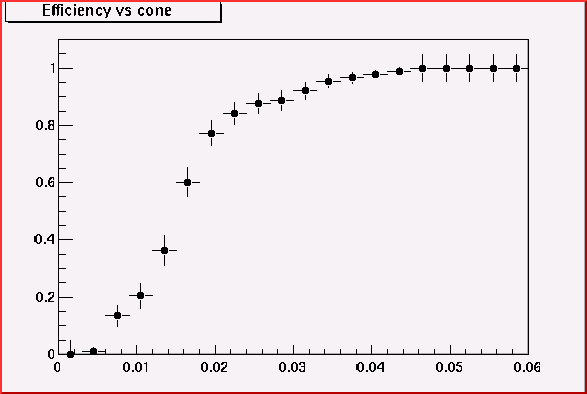
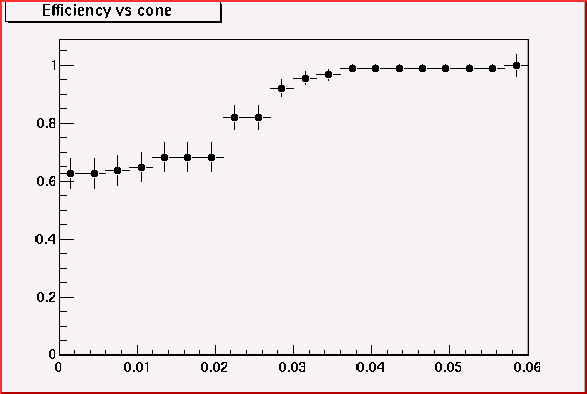
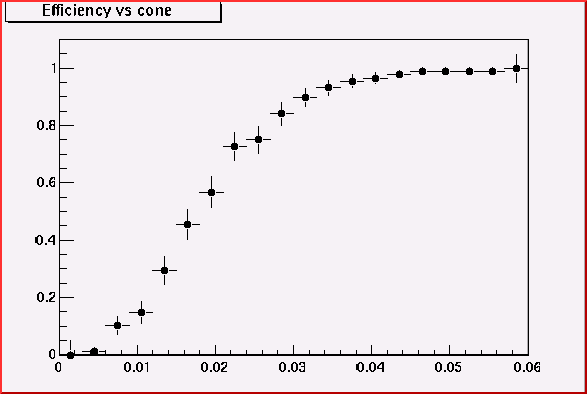
Here I use 200MeV pions and 500MeV pions in order to see the efficiency
versus cone-size plot.
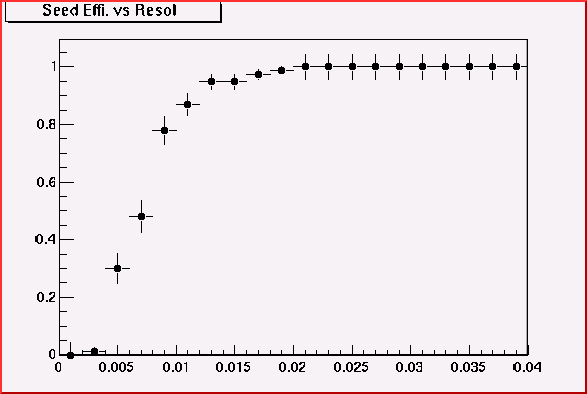 200MeV pion-
at theta = 42
200MeV pion-
at theta = 42
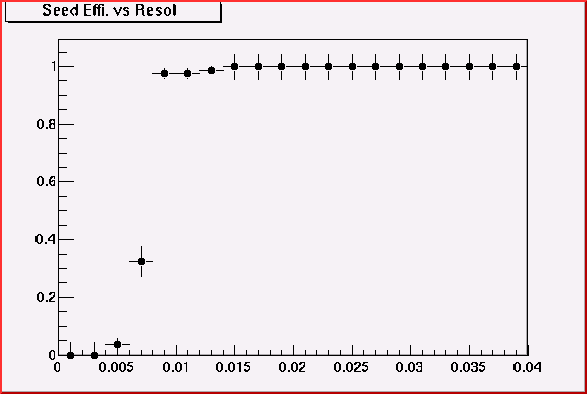 500MeV
pion+ at theta = 45
500MeV
pion+ at theta = 45
Thus cone size 0.02 is good enough to accept most of all 200MeV
pion. This value looks rather too big for higher momentum track but it's
safer. (We may loose some 100MeV pions)
Clean-up the random match-sticks using track seed information (theta & vertical constraints)
For a given track seed, we can have only a small number of allowed match sticks (1/p,theta) which are consistent with the seed (theta, phi).
For a given track seed,
1) we first extrapolate the track seed to the i'th layer in the vertical
view (y-axis). Hits compatible with the "y" value obtained from the extrapolation
are considered for generating the Hough match-sticks. Here we consider
that a hit is compatible with the track seed if
| y_hit - y_seed | < sqrt ( sigma_y_hit**2 + sigma_y_seed**2)
sigma_y_hit is simply a half of the pad size in Y.
sigma_y_seed is calculated from the cone size.
2) We then compare the theta values of Match-sticks (now having y information)
and the theta value of the seed. If
| theta_ms - theta_seed | < sigma_theta_seed
we accept the match-sticks. Actually, I use "eta" instead of "theta"
because track seed direction and cone size are given by "eta".
Now we need to optimize the eta and phi cuts.
Optimization of theta cut
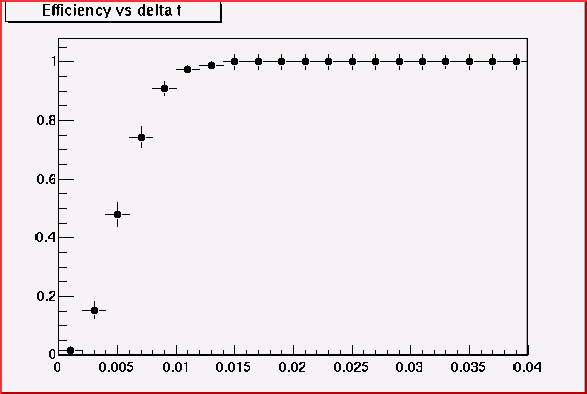 200MeV
pion- at theta=42
200MeV
pion- at theta=42
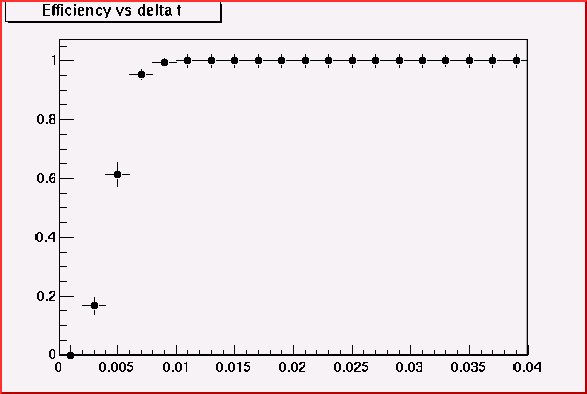 500MeV pion+
at theta=45
500MeV pion+
at theta=45
Not so different! 0.015 may be a good cut value.
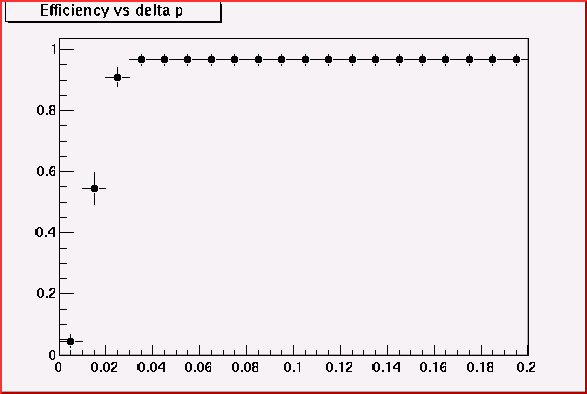
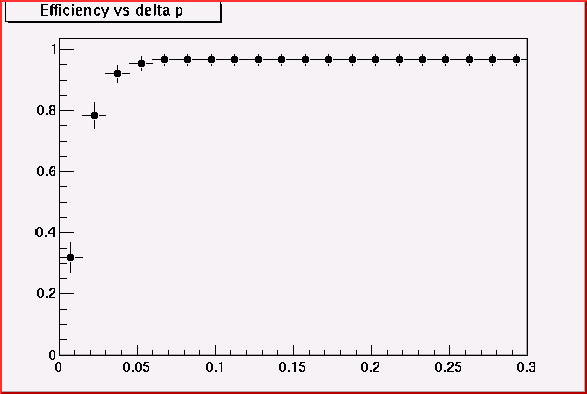
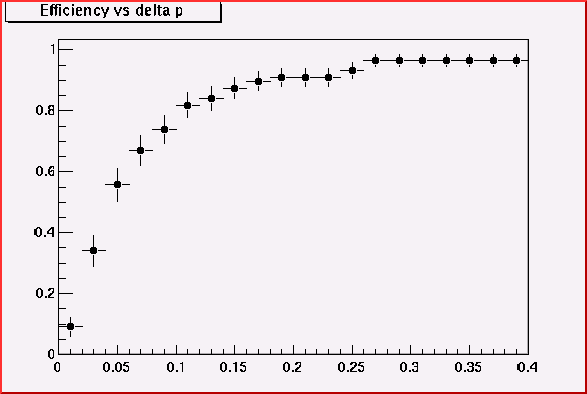
Optimization of Momentum cut
For the inner-to-outside curve finding algorithm. The match-sticks from the hits on the layer I to the hits on the layer J, i.e. match-stick IJ, are regarded as the initial curve candidates. When chain with the match-stick JK, only a certain variation of momentum should be allowed, otherwise we generate many ghost.
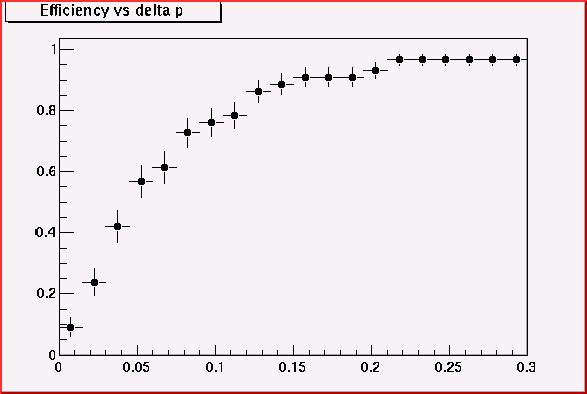 Momentum cut
& efficiency for match-stick JK
Momentum cut
& efficiency for match-stick JK
 Momentum cut
& efficiency for match-stick KM
Momentum cut
& efficiency for match-stick KM
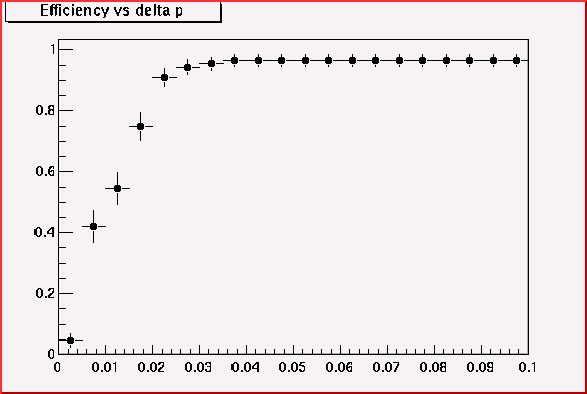 Momentum cut
& efficiency for match-stick MO
Momentum cut
& efficiency for match-stick MO
For the outer-to-inner curve finding algorithm, a match stick
MO becomes a curve candidate.